Joining Data¶
It’s rare that a data analysis involves only a single table of data. Typically you have many tables of data, and you must combine them to answer the questions that you’re interested in.
- Garrett Grolemund, Master Instructor, RStudio
Applied Review¶
Functions vs. Methods¶
- There are two types of operations in Python: functions and methods
- Functions are standalone operations from a module --
print()is a function:
print("Hello")
Hello
- Methods are operations that are encapsulated within Python objects --
DataFrame.head()is a method:
import pandas as pd
flights_df = pd.read_csv('../data/flights.csv')
flights_df.head()
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01 05:00:00 |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01 05:00:00 |
| 2 | 2013 | 1 | 1 | 542.0 | 540 | 2.0 | 923.0 | 850 | 33.0 | AA | 1141 | N619AA | JFK | MIA | 160.0 | 1089 | 5 | 40 | 2013-01-01 05:00:00 |
| 3 | 2013 | 1 | 1 | 544.0 | 545 | -1.0 | 1004.0 | 1022 | -18.0 | B6 | 725 | N804JB | JFK | BQN | 183.0 | 1576 | 5 | 45 | 2013-01-01 05:00:00 |
| 4 | 2013 | 1 | 1 | 554.0 | 600 | -6.0 | 812.0 | 837 | -25.0 | DL | 461 | N668DN | LGA | ATL | 116.0 | 762 | 6 | 0 | 2013-01-01 06:00:00 |
DataFrame Structure¶
- Each DataFrame variable is a Series and can be accessed with bracket subsetting notation:
DataFrame['SeriesName']
- The DataFrame has an Index that is visible on the far left side
General Model¶
Combining Data¶
- We frequently want to use more than one table at once, so we need to combine them in some way
- Because tables are two-dimensional, we can combine them vertically and horizontally
- Combining data vertically is known as appending/unioning/concatenating
- Combiding data horizontally is known as joining/merging
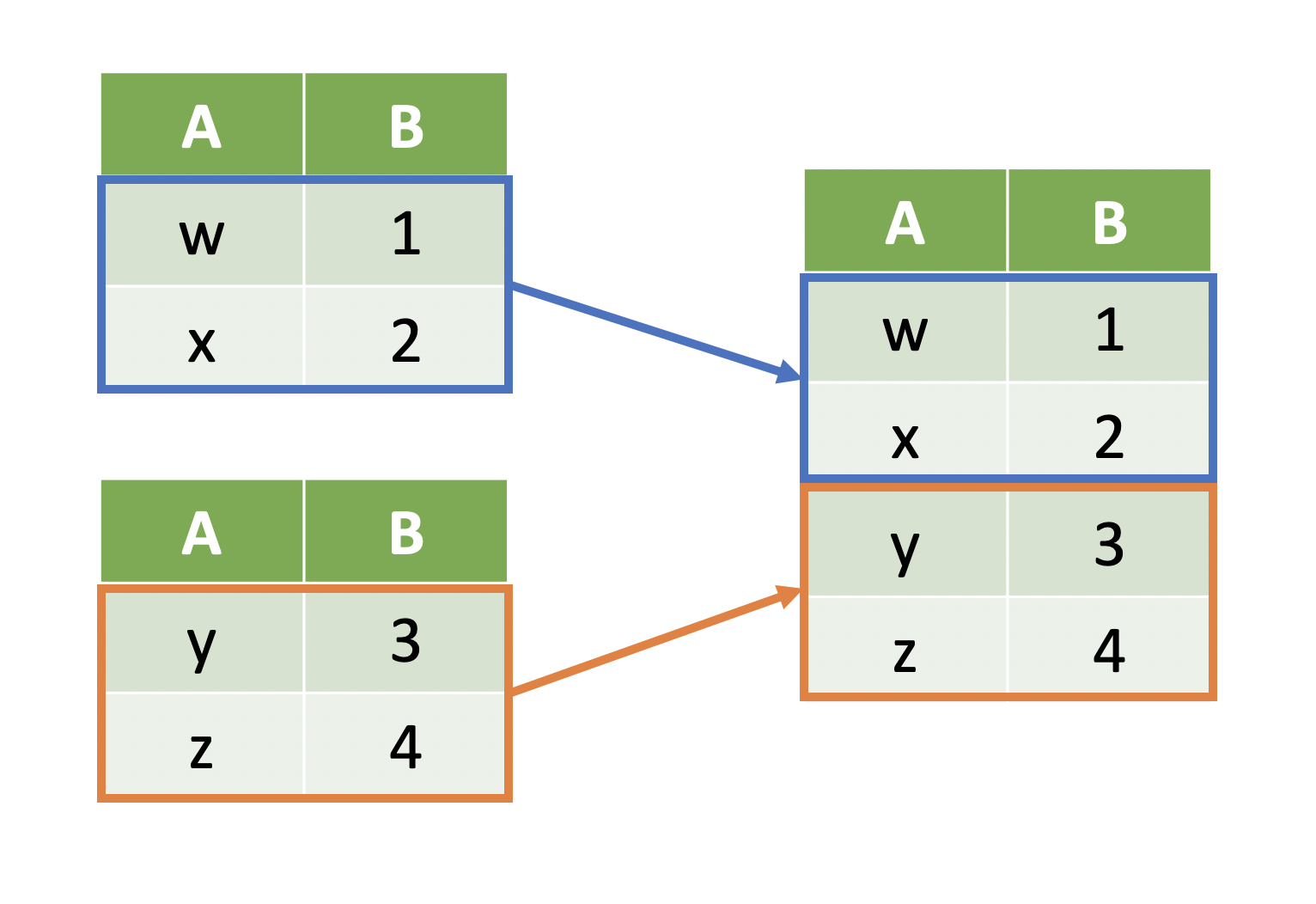
Appending Data Vertically¶
- When we combine data vertically, we are stacking tables on top of one another:
Note
This is particularly useful when all columns are the same between the two tables.
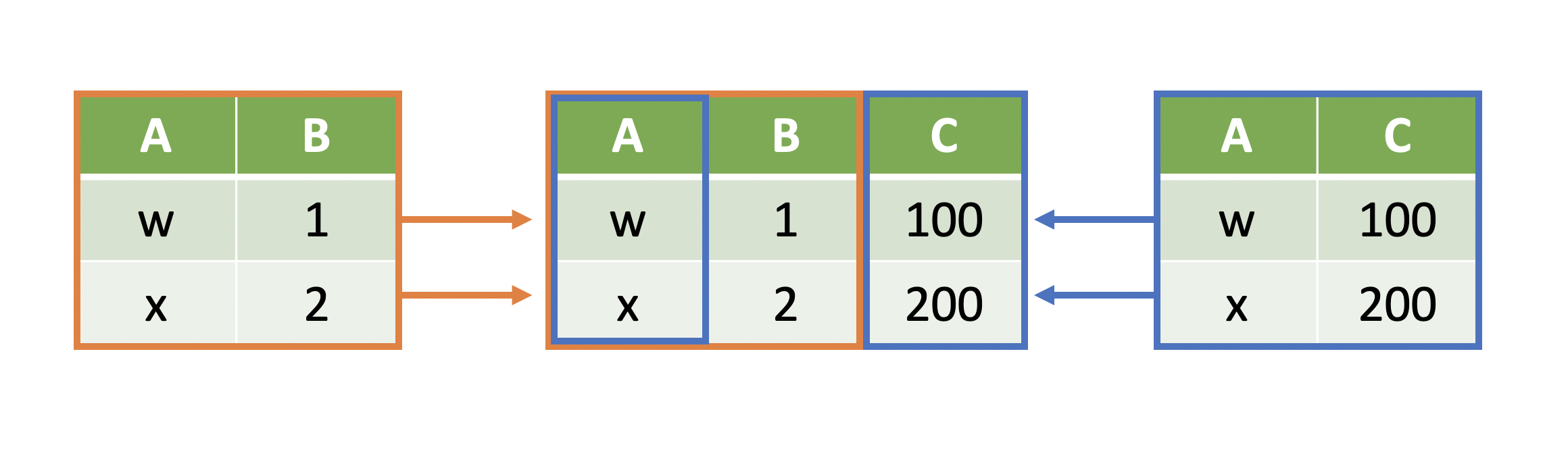
Joining Data Horizontally¶
- When we combine data horizontally, we are attaching the tables at their sides:
- Note that the rows do not need to be in the same order to join/merge two tables:
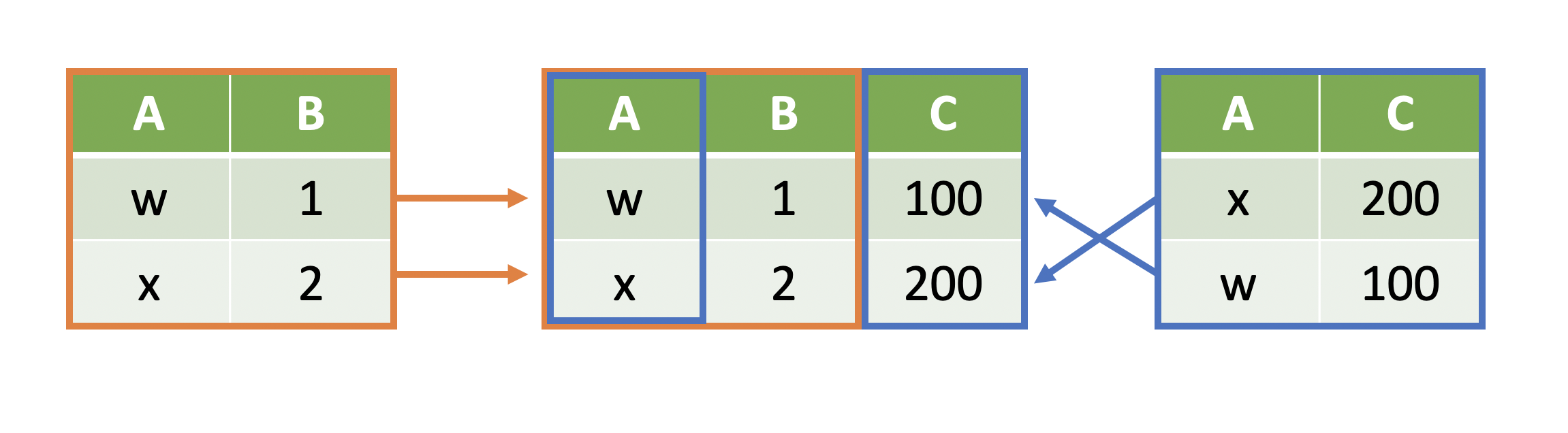
- The joining occurs by matching on a key column
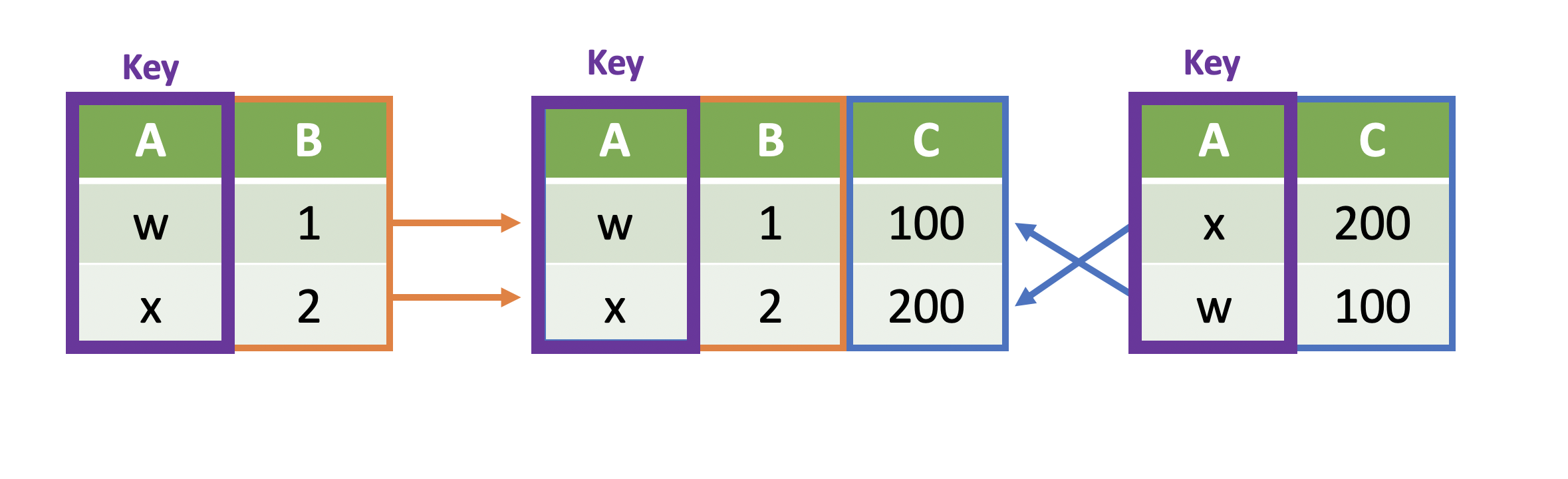
Combining DataFrames¶
Appending DataFrames¶
- When we combine DataFrames vertically, we want to stack two DataFrames on top of one another
- Let's start by creating two DataFrames with the same variables:
df_1 = pd.DataFrame({'x': [1, 2], 'y': ['a', 'b']})
df_1
| x | y | |
|---|---|---|
| 0 | 1 | a |
| 1 | 2 | b |
df_2 = pd.DataFrame({'x': [3, 4], 'y': ['c', 'd']})
df_2
| x | y | |
|---|---|---|
| 0 | 3 | c |
| 1 | 4 | d |
We can stack df_1 and df_2 on top of one another using the concat() function from pandas with a list:
pd.concat([df_1, df_2])
| x | y | |
|---|---|---|
| 0 | 1 | a |
| 1 | 2 | b |
| 0 | 3 | c |
| 1 | 4 | d |
Question
Does anything about this result seem weird?
The Index is repeating...
We can add the ignore_index = True to make the Index reset:
pd.concat([df_1, df_2], ignore_index = True)
| x | y | |
|---|---|---|
| 0 | 1 | a |
| 1 | 2 | b |
| 2 | 3 | c |
| 3 | 4 | d |
We can also use the DataFrame.reset_index() method:
pd.concat([df_1, df_2]).reset_index(drop = True)
| x | y | |
|---|---|---|
| 0 | 1 | a |
| 1 | 2 | b |
| 2 | 3 | c |
| 3 | 4 | d |
Caution!
Using pd.concat() to vertically combine dataframes should only be used when we know that the DataFrames' schemas are consistent.
Joining DataFrames¶
- Joining DataFrames may be one of the most important skills to learn in Python
- As a reminder, joining DataFrames is the horizontal combining of two DataFrames on some key column:
- We have
flights_df, but we need another DataFrame to join toflights_dfthat has a common key column
- As an example, assume we want to know which airline carried each flight in
flights_df:
airlines_df = pd.read_csv('../data/airlines.csv')
- Now let's examine the columns/variables in our two DataFrames using the
DataFrame.columnsattribute:
flights_df.columns
Index(['year', 'month', 'day', 'dep_time', 'sched_dep_time', 'dep_delay',
'arr_time', 'sched_arr_time', 'arr_delay', 'carrier', 'flight',
'tailnum', 'origin', 'dest', 'air_time', 'distance', 'hour', 'minute',
'time_hour'],
dtype='object')
airlines_df.columns
Index(['carrier', 'name'], dtype='object')
Question
Which column should be our key column?
The carrier column is our key because it's in both DataFrames.
Tip!
There is an intersection() method that makes it easy to find common columns between two DataFrames.
flights_df.columns.intersection(airlines_df.columns)
Index(['carrier'], dtype='object')
We can join/merge the DataFrames together using the merge() function:
pd.merge(flights_df, airlines_df, on = 'carrier').head(2)
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | name | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01 05:00:00 | United Air Lines Inc. |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01 05:00:00 | United Air Lines Inc. |
- This joined
flights_dfandairlines_dftogether to attach thenamefromairlines_dfto each flight
Your Turn¶
1. Import planes.csv into a DataFrame named planes_df
2. Identify the common column names between the two DataFrames.
3. Fill in the blanks below to join the flights_df to planes_df:
pd._____(flights_df, planes_df, on = '_____')
Join Types¶
Inner Joins¶
All of our joins have been inner joins:
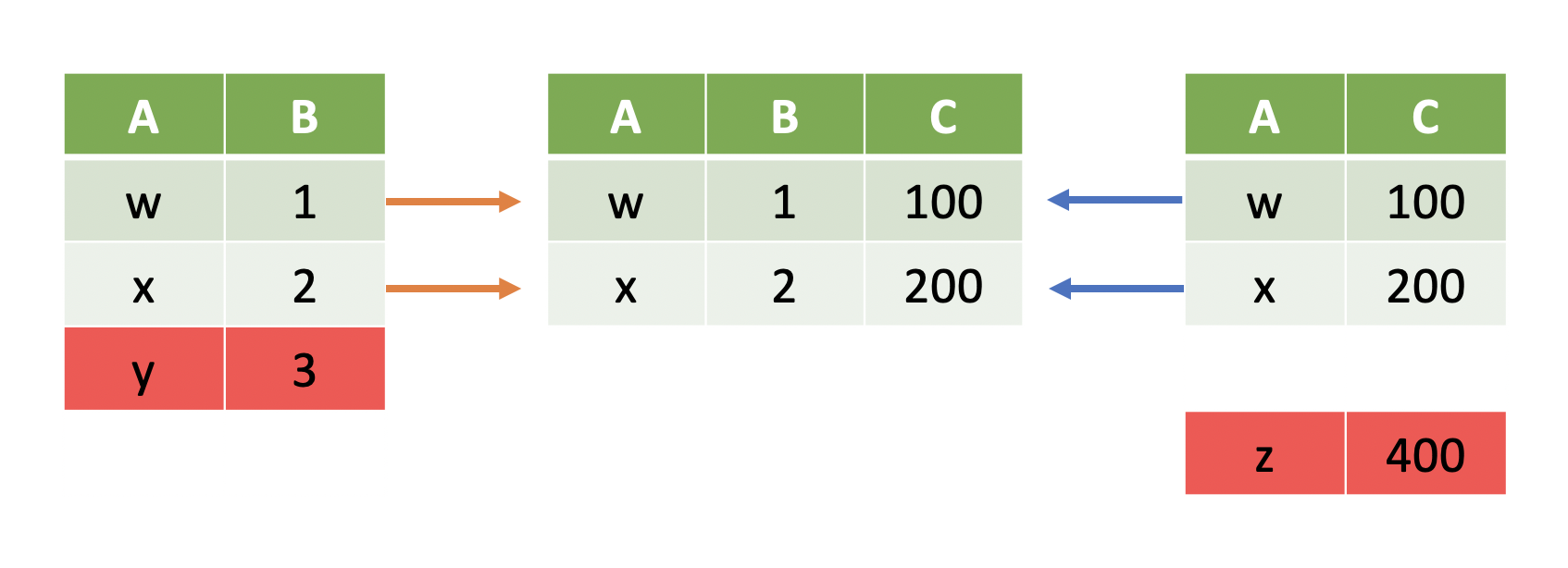
Note
Inner joins only keep rows where the key is in both tables.
Left Joins¶
Sometimes we only want to include data that is in the left table regardless of whether it's in the right table:
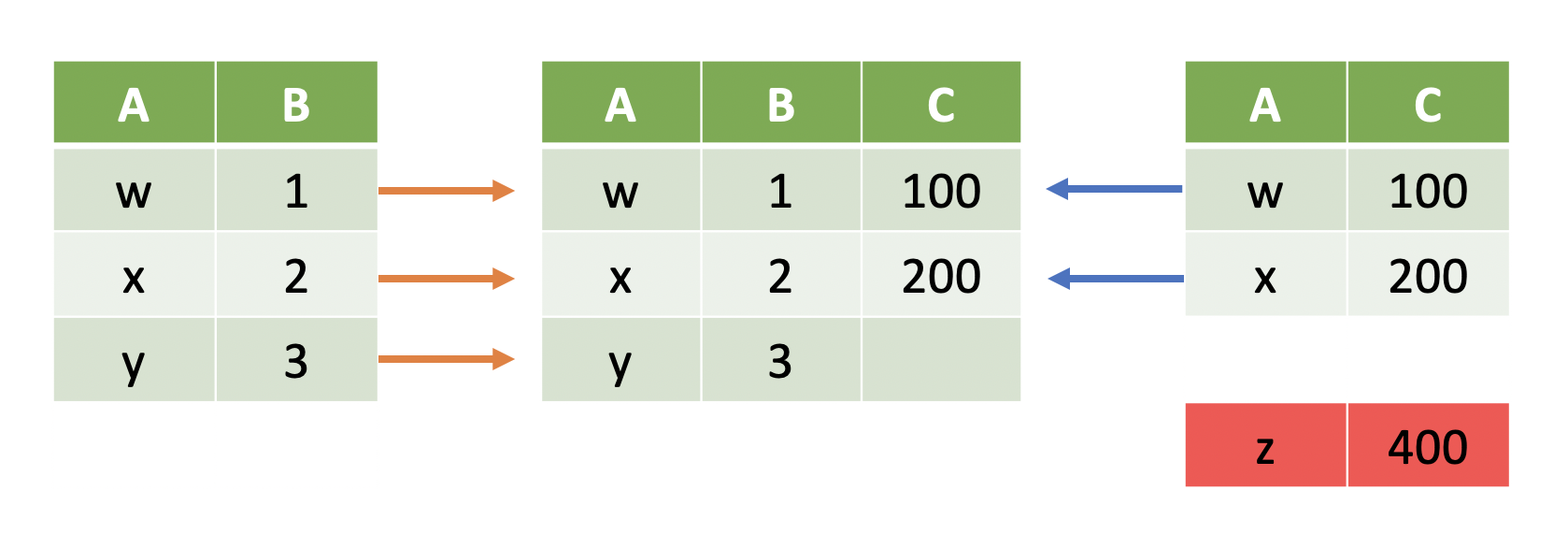
Note
Left outer joins, or simply left joins, keep rows where the key is in the left table.
Right Joins¶
Sometimes we only want to include data that is in the right table regardless of whether it's in the left table:
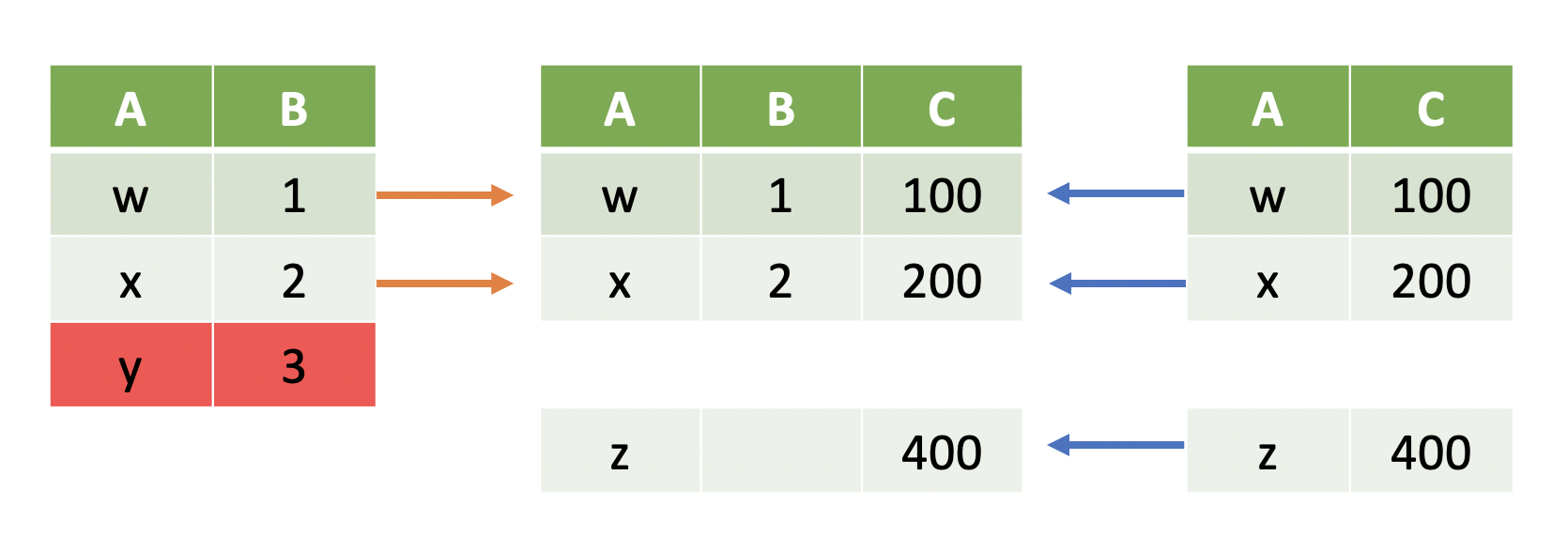
Note
Right outer joins, or simply right joins, keep rows where the key is in the right table.
Outer Joins¶
Sometimes we want to include all rows in either the left table or the right table:
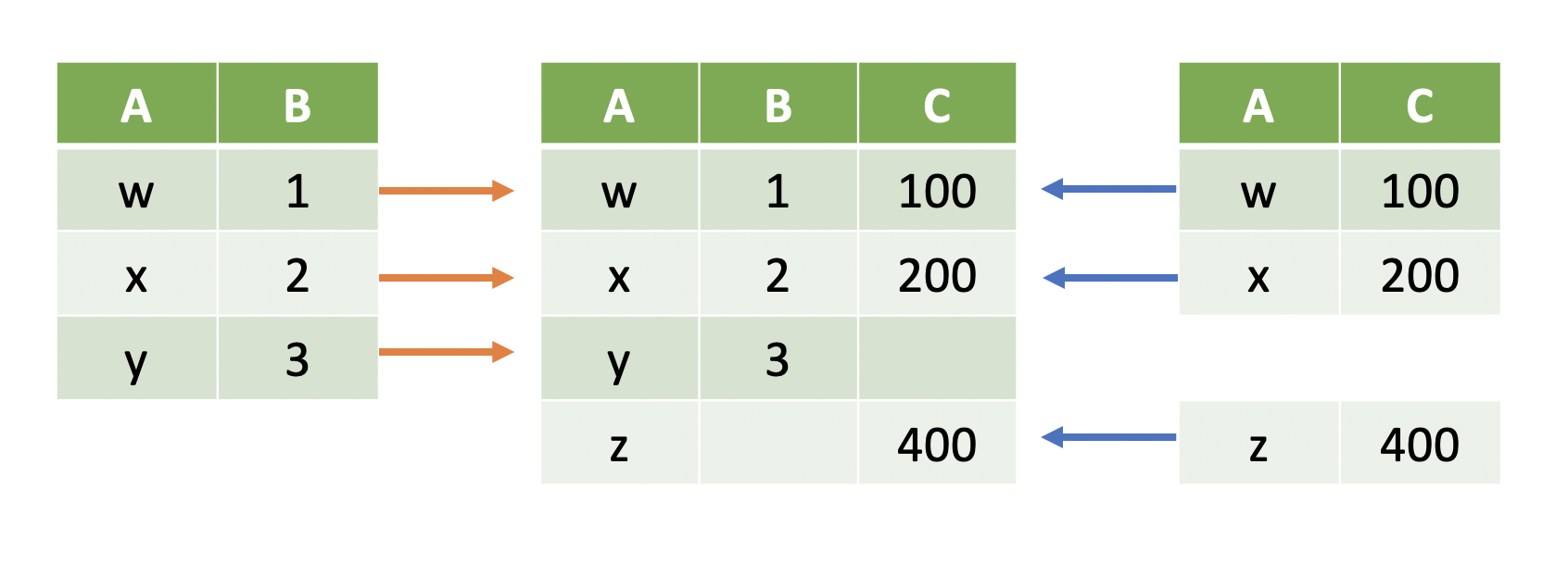
Note
Full outer joins keep all rows in both tables.
Applying Different Join Types¶
We can apply these different join types using the how parameter of the merge() function:
pd.merge(flights_df, airlines_df, on = 'carrier', how = 'inner').head(3)
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | name | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01 05:00:00 | United Air Lines Inc. |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01 05:00:00 | United Air Lines Inc. |
| 2 | 2013 | 1 | 1 | 554.0 | 558 | -4.0 | 740.0 | 728 | 12.0 | UA | 1696 | N39463 | EWR | ORD | 150.0 | 719 | 5 | 58 | 2013-01-01 05:00:00 | United Air Lines Inc. |
While how = 'inner' is the default, we can also use 'left', 'right', and 'outer':
pd.merge(flights_df, airlines_df, on = 'carrier', how = 'outer').head(3)
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | name | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01 05:00:00 | United Air Lines Inc. |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01 05:00:00 | United Air Lines Inc. |
| 2 | 2013 | 1 | 1 | 554.0 | 558 | -4.0 | 740.0 | 728 | 12.0 | UA | 1696 | N39463 | EWR | ORD | 150.0 | 719 | 5 | 58 | 2013-01-01 05:00:00 | United Air Lines Inc. |
Your Turn¶
What type of join includes the rows where the key is in the left table regardless of whether the key is in the right table?
Join the
flights_dftoplanes_dfand keep all rows from both tables.
Questions¶
Are there questions before we move on?