Summarizing Grouped Data¶
Applied Review¶
DataFrame Structure¶
- We will start by importing the
planesdata set as a DataFrame:
In [1]:
import pandas as pd
planes_df = pd.read_csv('../data/planes.csv')
- Each DataFrame variable is a Series and can be accessed with bracket subsetting notation:
DataFrame['SeriesName']
- The DataFrame has an Index that is visible the far left side
Summary Operations¶
- Summary operations occur when we collapse a Series or DataFrame down to a single row
- This is an aggregation of a variable across its rows
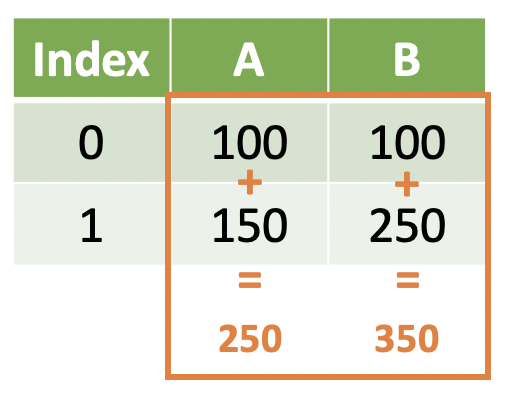
Summarizing Data Frames¶
- We can perform summary operations on DataFrames in a number of ways:
- Summary methods for a specific summary operation:
DataFrame.sum()
- Describe method for a collection of summary operations:
DataFrame.describe()
- Agg method for flexibility in summary operations:
DataFrame.agg({'VariableName': ['sum', 'mean']})
- An example of the agg method:
In [2]:
planes_df.agg({
'year': ['mean', 'median'],
'seats': ['mean', 'max']
})
Out[2]:
| year | seats | |
|---|---|---|
| mean | 2000.48401 | 154.316376 |
| median | 2001.00000 | NaN |
| max | NaN | 450.000000 |
Note
We will primarily use the .agg() method moving forward.
General Model¶
Variable Groups¶
- We can group DataFrame rows together by the value in a Series/variable
- If we "group by A", then rows with the same value in variable A are in the same group

- Note that groups do not need to be ordered by their values:

Question
Why might we be interested in grouping by a variable?
Summarizing by Groups¶
- When we've talked about summary operations, we've talked about collapsing a DataFrame to a single row
- This is not always the case -- we sometimes collapse to a single row per group
- This is known as a grouped aggregation:
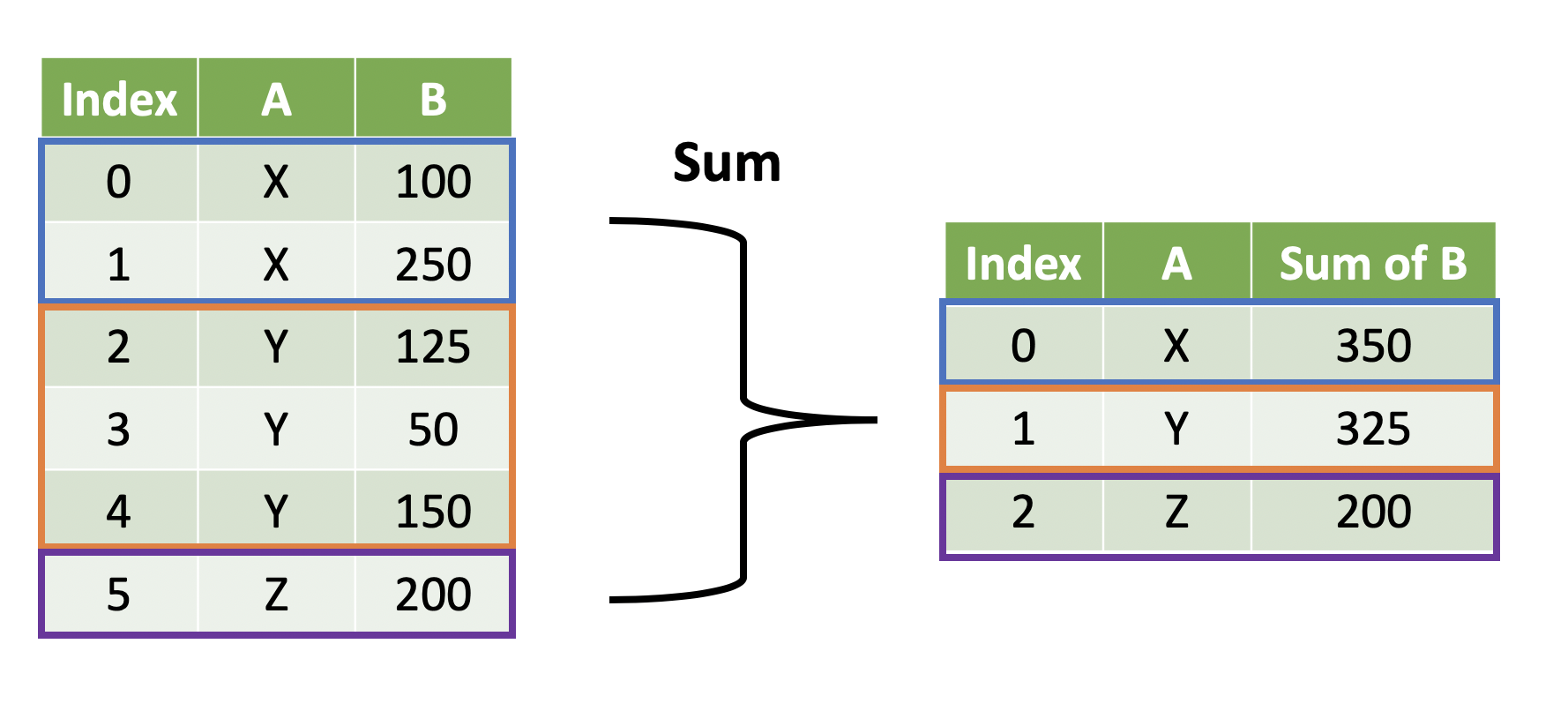
- This can be useful when we want to aggregate by cateogory:
- Maximum temperature by month
- Total home runs by team
- Total sales by geography
- Average number of seats by plane manufacturer
Question
What are common grouped aggregation metrics used in your industry/organization?
Summarizing Grouped Data¶
- When we summarize by groups, we can use the same aggregation methods we previously did
- Summary methods for a specific summary operation:
DataFrame.sum()
- Describe method for a collection of summary operations:
DataFrame.describe()
- Agg method for flexibility in summary operations:
DataFrame.agg({'VariableName': ['sum', 'mean']})
- The only difference is the need to set the DataFrame group prior to aggregating
Setting the DataFrame Group¶
- We can set the DataFrame group by calling the
DataFrame.groupby()method and passing a variable name:
In [3]:
planes_df.groupby('model')
Out[3]:
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x111554950>
- Notice that a DataFrame doesn't print when it's grouped
- The
groupby()method is just setting the group - you can see the changed DataFrame class:
In [4]:
type(planes_df.groupby('manufacturer'))
Out[4]:
pandas.core.groupby.generic.DataFrameGroupBy
- If we then call an aggregation method, we will see the DataFrame returned with the aggregated results:
In [5]:
(
planes_df.groupby('manufacturer')
.agg({'seats': ['mean', 'max']}).head()
)
Out[5]:
| seats | ||
|---|---|---|
| mean | max | |
| manufacturer | ||
| AGUSTA SPA | 8.000000 | 8 |
| AIRBUS | 221.202381 | 379 |
| AIRBUS INDUSTRIE | 187.402500 | 379 |
| AMERICAN AIRCRAFT INC | 2.000000 | 2 |
| AVIAT AIRCRAFT INC | 2.000000 | 2 |
- This process always follows this model:
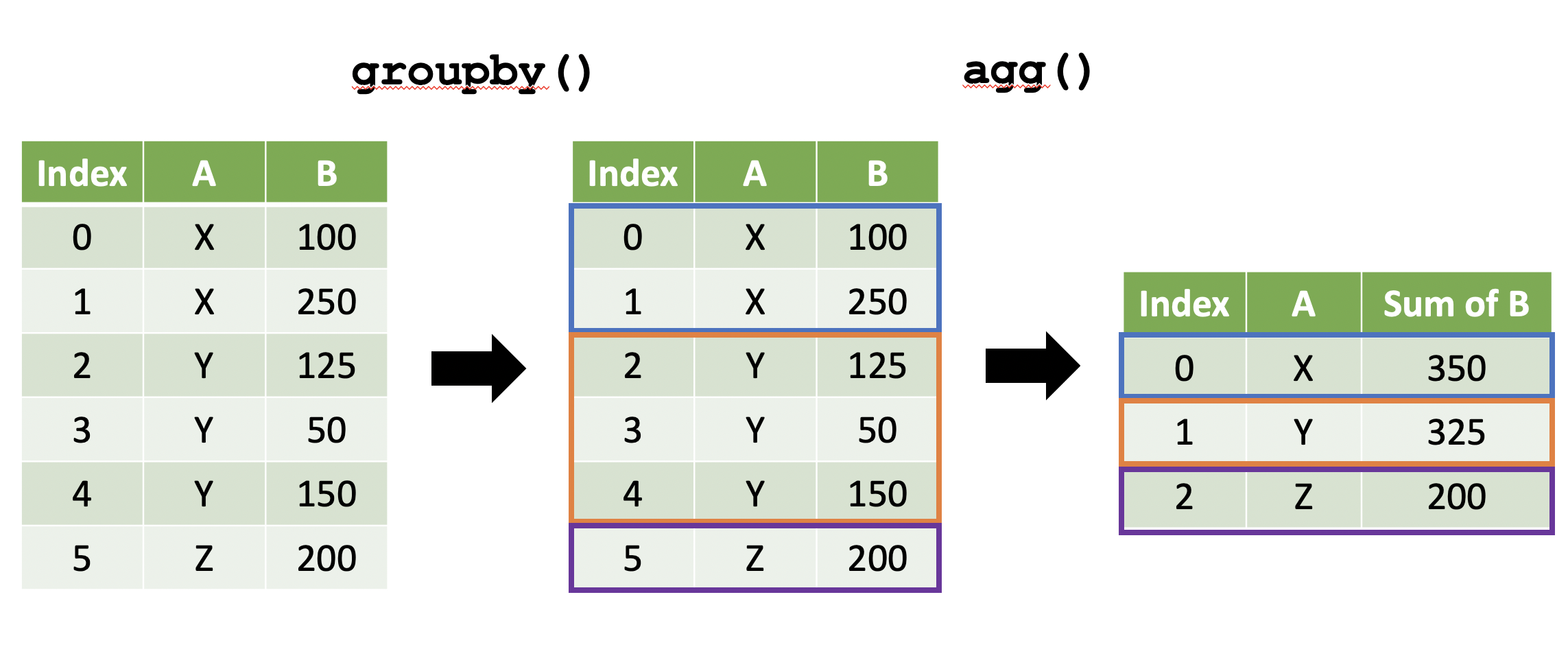
- Notice that the grouped variable becomes the Index in our example!
In [6]:
(
planes_df.groupby('manufacturer')
.agg({'seats': ['mean', 'max']}).head()
)
Out[6]:
| seats | ||
|---|---|---|
| mean | max | |
| manufacturer | ||
| AGUSTA SPA | 8.000000 | 8 |
| AIRBUS | 221.202381 | 379 |
| AIRBUS INDUSTRIE | 187.402500 | 379 |
| AMERICAN AIRCRAFT INC | 2.000000 | 2 |
| AVIAT AIRCRAFT INC | 2.000000 | 2 |
In [7]:
(
planes_df.groupby('manufacturer')
.agg({'seats': ['mean', 'max']}).index
)
Out[7]:
Index(['AGUSTA SPA', 'AIRBUS', 'AIRBUS INDUSTRIE', 'AMERICAN AIRCRAFT INC',
'AVIAT AIRCRAFT INC', 'AVIONS MARCEL DASSAULT', 'BARKER JACK L',
'BEECH', 'BELL', 'BOEING', 'BOMBARDIER INC', 'CANADAIR', 'CANADAIR LTD',
'CESSNA', 'CIRRUS DESIGN CORP', 'DEHAVILLAND', 'DOUGLAS', 'EMBRAER',
'FRIEDEMANN JON', 'GULFSTREAM AEROSPACE', 'HURLEY JAMES LARRY',
'JOHN G HESS', 'KILDALL GARY', 'LAMBERT RICHARD', 'LEARJET INC',
'LEBLANC GLENN T', 'MARZ BARRY', 'MCDONNELL DOUGLAS',
'MCDONNELL DOUGLAS AIRCRAFT CO', 'MCDONNELL DOUGLAS CORPORATION',
'PAIR MIKE E', 'PIPER', 'ROBINSON HELICOPTER CO', 'SIKORSKY',
'STEWART MACO'],
dtype='object', name='manufacturer')
Groups as Indexes¶
- This is the default behavior of
pandas, and probably howpandaswants to be used
- This is the fastest way to do it, but it's a matter of less than a millisecond
- You aren't always going to see people group by the Index...
Groups as Variables¶
- Instead of setting the group as the Index, we can set the group as a variable
- The grouped variable can remain a Series/variable by adding the
as_index = Falseparameter/argument togroupby():
In [8]:
(
planes_df.groupby('manufacturer', as_index = False)
.agg({'seats': ['mean', 'max']}).head()
)
Out[8]:
| manufacturer | seats | ||
|---|---|---|---|
| mean | max | ||
| 0 | AGUSTA SPA | 8.000000 | 8 |
| 1 | AIRBUS | 221.202381 | 379 |
| 2 | AIRBUS INDUSTRIE | 187.402500 | 379 |
| 3 | AMERICAN AIRCRAFT INC | 2.000000 | 2 |
| 4 | AVIAT AIRCRAFT INC | 2.000000 | 2 |
Grouping by Multiple Variables¶
- Sometimes we have multiple categories by which we'd like to group
- To extend our example, assume we want to find the average number of seats by plane manufacturer AND plane year
- We can pass a list of variable names to the
groupby()method:
In [9]:
(
planes_df.groupby(['manufacturer', 'year'], as_index = False)
.agg({'seats': ['mean', 'max']}).head()
)
Out[9]:
| manufacturer | year | seats | ||
|---|---|---|---|---|
| mean | max | |||
| 0 | AGUSTA SPA | 2001.0 | 8.000000 | 8 |
| 1 | AIRBUS | 2002.0 | 173.800000 | 200 |
| 2 | AIRBUS | 2003.0 | 174.966667 | 200 |
| 3 | AIRBUS | 2004.0 | 217.000000 | 379 |
| 4 | AIRBUS | 2005.0 | 197.000000 | 379 |
Your Turn¶
1. What is meant by "find the minimum number of seats on a plane by year"?
2. Fix the below code to find the minimum number of seats on a plane by year:
planes_df.groupby('_____').agg({'_____': ['min']})
3. What is the Index of the result?
Questions¶
Are there any questions before we move on?