Selecting and Filtering¶
“Every second of every day, our senses bring in way too much data than we can possibly process in our brains.”
- Peter Diamandis, Founder of the X-Prize for human-AI collaboration
Applied Review¶
Data Structures and the DataFrame Class¶
- Data is frequently represented inside a DataFrame - a class from the
pandaslibrary that is similar to a table or dataset
- Each DataFrame object has rows and columns
- The DataFrame class has methods (built-in operations) for common tasks and attributes (stored data) of common information
- Other structures exist, too - lists, dicts, tuples, etc.
Importing Data¶
- Tabular data can be imported into DataFrames using the
pd.read_csv()function - there are parameters for different options
import pandas as pd
planes_df = pd.read_csv('../data/planes.csv')
- Other data formats like JSON (key-value pairs) and Pickle (native Python) can be imported using the
withstatement and respective functions:- JSON files use the
load()function from thejsonlibrary - Pickle files use the
load()function from thepicklelibrary
- JSON files use the
General Model¶
Subsetting Dimensions¶
- We don't always want all of the data in a DataFrame, so we need to take subsets of the DataFrame.
- In general, subsetting is extracting a small portion of a DataFrame -- making the DataFrame smaller.
- Since the DataFrame is two-dimensional, there are two dimensions on which to subset.
Dimension 1: We may only want to consider certain variables.
For example, we may only care about the year and engines variables:

We call this selecting columns/variables -- this is similar to SQL's SELECT or R's dplyr package's select().
Dimension 2: We may only want to consider certain cases.
For example, we may only care about the cases where the manufacturer is Embraer.

We call this filtering or slicing -- this is similar to SQL's WHERE or R's dplyr package's filter() or slice().
And we can combine these two options to subset in both dimensions -- the year and engines variables where the manufacturer is Embraer:

Subsetting into a New DataFrame¶
In the previous example, we want to do two things using planes_df:
- select the
yearandenginesvariables - filter to cases where the manufacturer is Embraer
But we also want to return a new DataFrame -- not just highlight certain cells.
In other words, we want to turn this:
planes_df.head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 1 | N102UW | 1998.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 2 | N103US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 3 | N104UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
Into this:

So we really have a third need: return the resulting DataFrame so we can continue our analysis:
- select the
yearandenginesvariables - filter to cases where the manufacturer is Embraer
- Return a DataFrame to continue the analysis
Subsetting Variables¶
Recall that the subsetting of variables/columns is called selecting variables/columns.
In a simple example, we can select a single variable using bracket subsetting notation:
planes_df['year'].head()
0 2004.0 1 1998.0 2 1999.0 3 1999.0 4 2002.0 Name: year, dtype: float64
Notice the head() method also works on planes_df['year'] to return the first five elements.
Question
What is the data type of planes_df['year']?
This returns pandas.core.series.Series, referred to simply as a "Series", rather than a DataFrame.
type(planes_df['year'])
pandas.core.series.Series
This is okay -- the Series is a popular data structure in Python. Recall:
- A Series is a one-dimensional data structure -- this is similar to a Python
list
- Note that all objects in a Series must be of the same type
- Each DataFrame can be thought of as a list of equal-length Series (plus an Index)
This visual of a Series and DataFrame may be helpful:
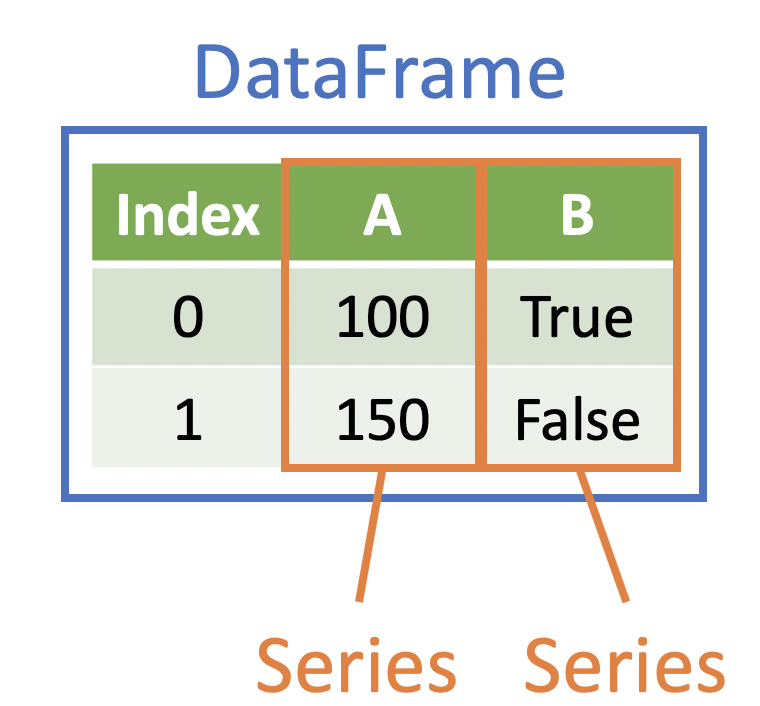
Series can be useful for other things, and we will cover that later -- but for now, we are interested in returning a DataFrame rather than a series.
We can select a single variable and return a DataFrame by still using bracket subsetting notation, but this time we will pass a list of variables names:
planes_df[['year']].head()
| year | |
|---|---|
| 0 | 2004.0 |
| 1 | 1998.0 |
| 2 | 1999.0 |
| 3 | 1999.0 |
| 4 | 2002.0 |
And we can see that we've returned a DataFrame:
type(planes_df[['year']].head())
pandas.core.frame.DataFrame
Question
What's another advantage of this passing a list?
Passing a list into the bracket subsetting notation allows us to select multiple variables at once:
planes_df[['year', 'engines']].head()
| year | engines | |
|---|---|---|
| 0 | 2004.0 | 2 |
| 1 | 1998.0 | 2 |
| 2 | 1999.0 | 2 |
| 3 | 1999.0 | 2 |
| 4 | 2002.0 | 2 |
In another example, assume we are interested in the model of plane, number of seats and engine type:
planes_df[['model', 'seats', 'engine']].head()
| model | seats | engine | |
|---|---|---|---|
| 0 | EMB-145XR | 55 | Turbo-fan |
| 1 | A320-214 | 182 | Turbo-fan |
| 2 | A320-214 | 182 | Turbo-fan |
| 3 | A320-214 | 182 | Turbo-fan |
| 4 | EMB-145LR | 55 | Turbo-fan |
Your Turn¶
1. ______ is a common term for subsetting DataFrame variables.
2. What type of object is a DataFrame column?
3. What will be returned by the following code?
planes_df['type', 'model']
Subsetting Cases¶
When we subset cases/records/rows we primarily use two names: slicing and filtering, but these are not the same:
- slicing, similar to row indexing, subsets cases by the value of the Index
- filtering subsets cases using a conditional test
Slicing Cases¶
Remember that all DataFrames have an Index:
planes_df.head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 1 | N102UW | 1998.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 2 | N103US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 3 | N104UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
We can slice cases/rows using the values in the Index and bracket subsetting notation. It's common practice to use .loc to slice cases/rows:
planes_df.loc[0:5]
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 1 | N102UW | 1998.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 2 | N103US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 3 | N104UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
| 5 | N105UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
Note
Note that since this is not "indexing", the last element is inclusive.
We can also pass a list of Index values:
planes_df.loc[[0, 2, 4, 6, 8]]
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 2 | N103US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
| 6 | N107US | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
| 8 | N109UW | 1999.0 | Fixed wing multi engine | AIRBUS INDUSTRIE | A320-214 | 2 | 182 | NaN | Turbo-fan |
Filtering Cases¶
We can filter cases/rows using a logical sequence equal in length to the number of rows in the DataFrame.
Continuing our example, assume we want to determine whether each case's manufacturer is Embraer. We can use the manufacturer Series and a logical equivalency test to find the result for each row:
planes_df['manufacturer'] == 'EMBRAER'
0 True
1 False
2 False
3 False
4 True
...
3317 False
3318 False
3319 False
3320 False
3321 False
Name: manufacturer, Length: 3322, dtype: bool
We can use this resulting logical sequence to test filter cases -- rows that are True will be returned while those that are False will be removed:
planes_df[planes_df['manufacturer'] == 'EMBRAER'].head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
| 10 | N11106 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 11 | N11107 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 12 | N11109 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
This also works with .loc:
planes_df.loc[planes_df['manufacturer'] == 'EMBRAER'].head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 4 | N10575 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145LR | 2 | 55 | NaN | Turbo-fan |
| 10 | N11106 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 11 | N11107 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 12 | N11109 | 2002.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
Any conditional test can be used to filter DataFrame rows:
planes_df.loc[planes_df['year'] > 2002].head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | N10156 | 2004.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 15 | N11121 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 16 | N11127 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 17 | N11137 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 18 | N11140 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
And multiple conditional tests can be combined using logical operators:
planes_df.loc[(planes_df['year'] > 2002) & (planes_df['year'] < 2004)].head()
| tailnum | year | type | manufacturer | model | engines | seats | speed | engine | |
|---|---|---|---|---|---|---|---|---|---|
| 15 | N11121 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 16 | N11127 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 17 | N11137 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 18 | N11140 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
| 19 | N11150 | 2003.0 | Fixed wing multi engine | EMBRAER | EMB-145XR | 2 | 55 | NaN | Turbo-fan |
Note
Note that each condition is wrapped in parentheses -- this is required.
Your Turn¶
What's the difference between slicing cases and filtering cases?
Fill in the blanks to fix the following code to find planes that have more than three engines:
planes_df.loc[______['______'] > 3]
Selecting Variables and Filtering Cases¶
If we want to select variables and filter cases at the same time, we have a few options:
- Sequential operations
- Simultaneous operations
Sequential Operations¶
We can use what we've previously learned to select variables and filter cases in multiple steps:
planes_df_filtered = planes_df.loc[planes_df['manufacturer'] == 'EMBRAER']
planes_df_filtered_and_selected = planes_df_filtered[['year', 'engines']]
planes_df_filtered_and_selected.head()
| year | engines | |
|---|---|---|
| 0 | 2004.0 | 2 |
| 4 | 2002.0 | 2 |
| 10 | 2002.0 | 2 |
| 11 | 2002.0 | 2 |
| 12 | 2002.0 | 2 |
This is a good way to learn how to select and filter independently, and it also reads very clearly.
Simultaneous Operations¶
However, we can also do both selecting and filtering in a single step with .loc:
planes_df.loc[planes_df['manufacturer'] == 'EMBRAER', ['year', 'engines']].head()
| year | engines | |
|---|---|---|
| 0 | 2004.0 | 2 |
| 4 | 2002.0 | 2 |
| 10 | 2002.0 | 2 |
| 11 | 2002.0 | 2 |
| 12 | 2002.0 | 2 |
This option is more succinct and also reduces programming time.
Your Turn¶
Subset planes_df to only include planes made by Boeing and the seats and model variables.
Questions¶
Are there any questions before we move on?