The Python Data Science Ecosystem¶
Applied Review¶
So far in this course, we've talked about the following tools:
- Python itself: control flow, functions, etc
- Jupyter
- Pandas
- The shell
- Conda
If you took the introductory course with us, we also discussed matplotlib and seaborn.
And this afternoon, we'll talk about scikit-learn.
And that was a lot! But in this session we're going to talk about the things we simply can't cover -- the Python ecosystem is expansive and full of useful technologies.
Why is there so much?¶
A few reasons:
- Python is very popular in many different fields (and growing in popularity in others): data science, web development, shell scripting, and more.
- Open ecosystems encourage rapid, iterative tool creation. Have an idea? You can build it and publish it for everyone to use.
- Many huge companies use Python very heavily (Netflix, YouTube, Uber...) and sometimes open-source the tools they create for internal use.
Jake Vanderplas' Python Data Science Ecosystem¶
In 2017, Jake Vanderplas (Python author, developer, and advocate) spoke at PyCon (the biggest Python conference) about the Python data science ecosystem. Let's look at his diagram.
Notably, the diagram is arranged to show that higher-level libraries are built upon lower-level libraries -- a common development approach in open ecoystems.
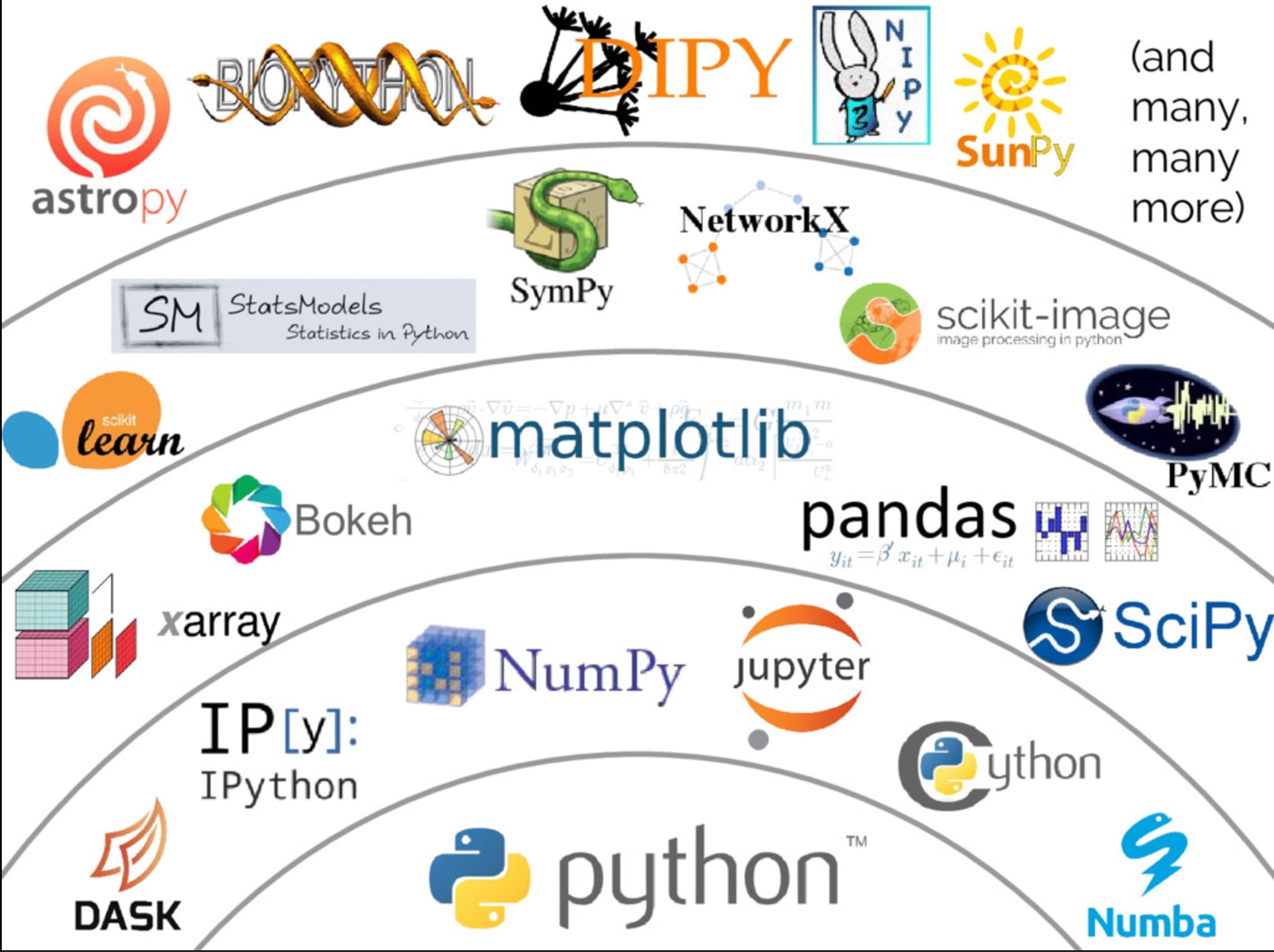
Which of these should you think about using?
- scikit-image for image processing
- statsmodels for statistical testing and inference (vs scikit-learn, which really excels at modeling)
- Cython for low-level performance optimization
- NetworkX for graphs (in the computer science sense)
- astropy and Biopython if you work in one of those domains
Paco Nathan's Python Data Science Landscape¶
More recently, Paco Nathan (data science researcher and frequent conference speaker) wrote a blog post in which he illustrated the current Python data science landscape.
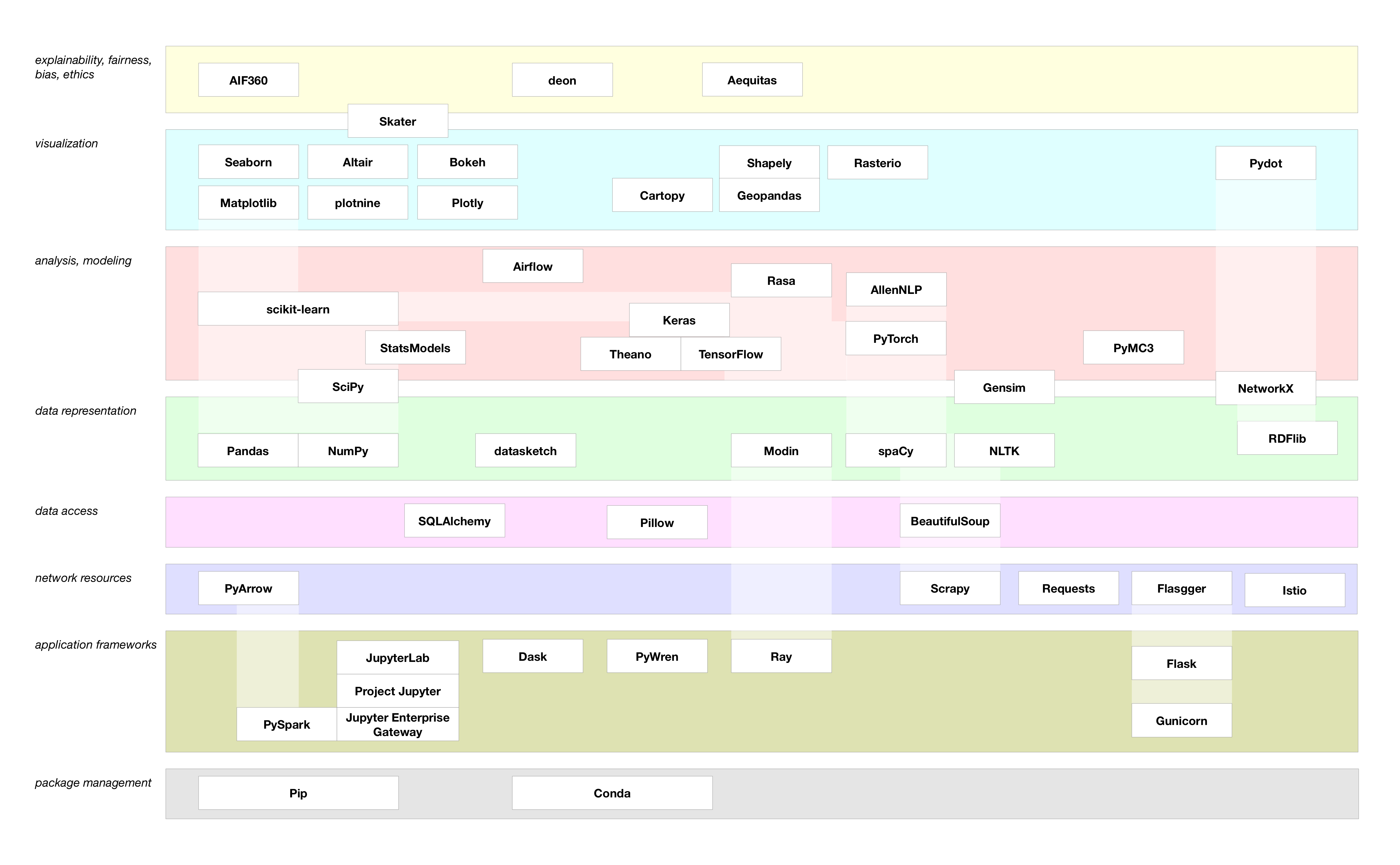
Many similarities to the other graphic, but also many new technologies!
Which new things here should you think about using?
- Flask for developing simple web apps
- Ray and PySpark for distributed computing (working with really big data)
- Altair for intuitive, declarative-style plotting.
- Plotly for interactive graphics and dashboards
- SQLAlchemy for interacting with databases (Oracle, SQLServer, MySQL)
- Requests, Scrapy, and BeautifulSoup for pulling data from the internet
- Keras and Tensorflow for deep learning -- useful for modeling with perceptual data, like images or sounds
- Airflow for candence- or trigger-based automation
- spaCy for cutting-edge natural language processing
How To Keep Up¶
Following the developments in such a full space can be daunting, but we recommend a few things:
- Subscribe to newsletters. The O'Reilly Data Newsletter and Python Weekly are reliably excellent.
- Listen to podcasts. Talk Python to Me and Python Bytes are both good. While neither is data science-specific, they cover a wide range of topics and ideas.
- Google! We've discovered many good packages by searching for something specific. For example, many services offer a Python package so you can interact with them programmatically. I use the Todoist API to automatically update my todo-list on a regular cadence.
Questions¶
Are there any tasks you do regularly that you think might have packages?
Are there any tools we saw above that you'd like to hear more about?
Cheat Sheet¶
This section introduced a lot of new packages and tools. We'd like to leave you with a cheat sheet to refer to in the future when you're thinking about what Python package might be a good fit for your needs.
| Topic | Relevant Packages | Are Any Especially Beginner-Friendly? |
|---|---|---|
| Plotting | matplotlib, seaborn, Bokeh, altair, plotly | seaborn, altair |
| Database interaction | sqlalchemy | sqlalchemy |
| Deep Learning | keras, tensorflow | keras |
| Web Development | flask | |
| Getting Data from the Web | requests, scrapy, beautifulsoup | requests |
| Statistical Modeling | scikit-learn, statsmodels | |
| Distributed Computing | pyspark |