Introductions¶
Gus Powers¶
 |
Lead Data Scientist at 84.51°
Academic
Contact
|
Jay Cunningham¶
 |
Lead Data Scientist at 84.51°
Academic
Contact
|
Your Turn¶
We'll go around the room. Please share:
- Your name
- Your job or field
- How you hope to use Python in the future
Course¶
Defining Data Science¶
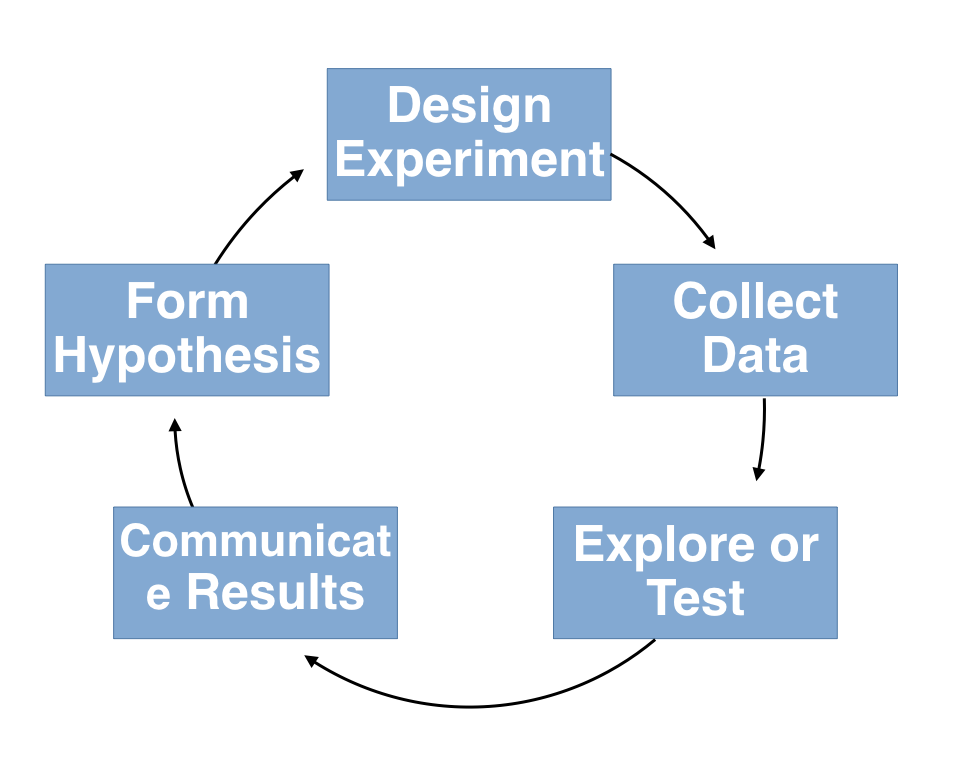
Data Science and Technology¶
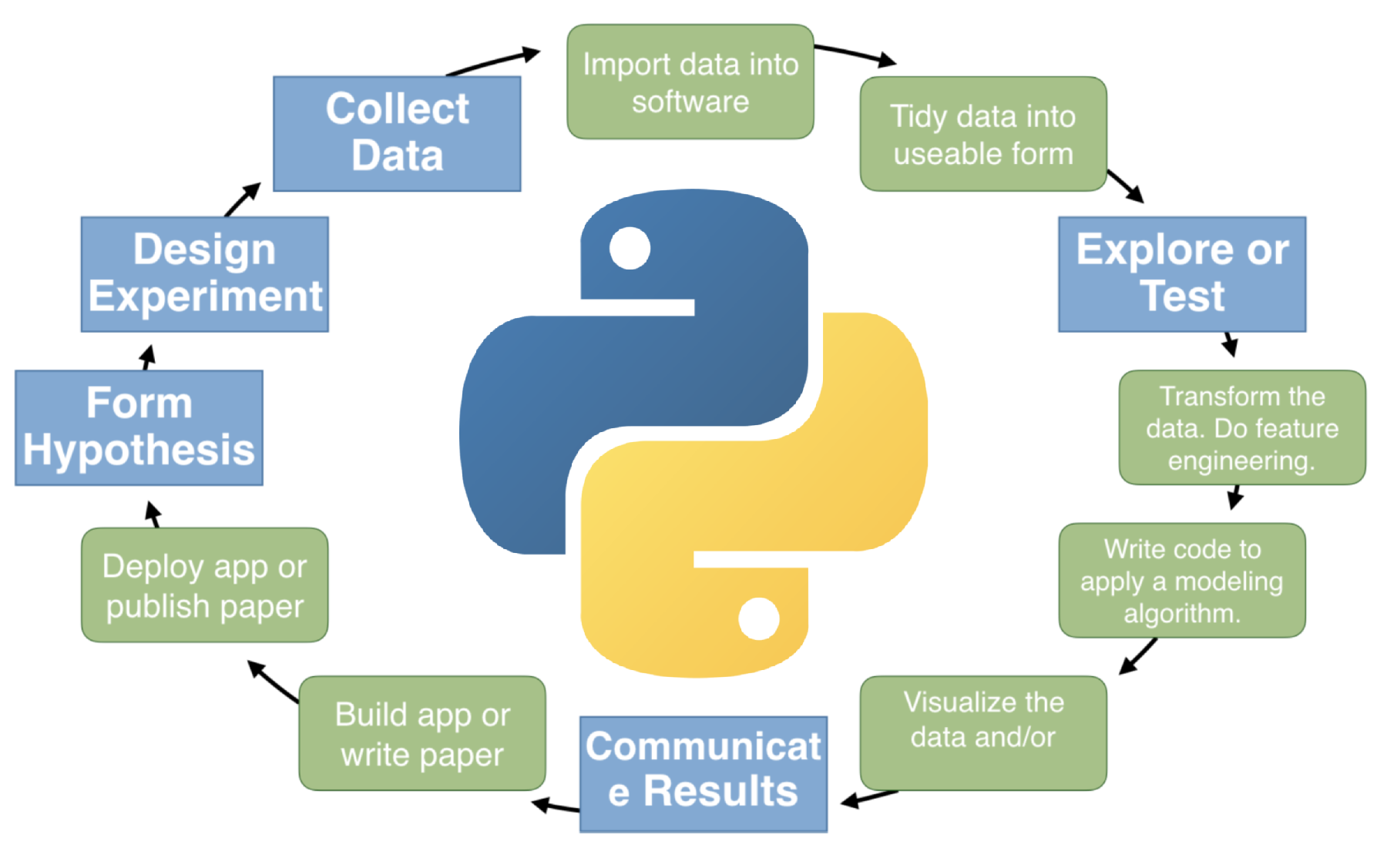
Applied Data Science¶

Course Objectives¶
The following are the primary learning objectives of this course:
- Learn to use control flow and custom functions to work with data more efficiently.
- Build awareness and basic skills in working with Python from the shell and its environments.
- Gain exposure to Python's data science ecosystem and modeling via scikit-learn.
Course Agenda¶
| Day | Topic | Time |
|---|---|---|
| 1 | Introductions | 12:45 - 1:00 |
| Setting the Stage | 1:00 - 1:30 | |
| Conditions | 1:30 - 2:15 | |
| Break | 2:15 - 2:30 | |
| Iterations | 2:30 - 3:45 | |
| Q&A | 3:45 - 4:15 | |
| 2 | Q&A | 12:45 - 1:15 |
| Functions | 1:15 - 2:15 | |
| Applying Functions to pandas Data Frames | 2:15 - 2:45 | |
| Break | 2:45 - 3:00 | |
| Case Study, pt. 1 | 3:00 - 4:00 | |
| Q&A | 4:00 - 4:15 |
| Day | Topic | Time |
|---|---|---|
| 3 | Q&A | 12:45 - 1:15 |
| Case Study Review, pt. 1 | 1:15 - 1:45 | |
| Python from the Shell | 1:45 - 2:45 | |
| Break | 2:45 - 3:00 | |
| Kernels and Environments | 3:00 - 3:45 | |
| Python Data Science Ecosystem | 3:45 - 4:00 | |
| Q&A | 4:00 - 4:15 | |
| 4 | Q&A | 12:45 - 1:15 |
| Modeling with scikit-learn | 1:15 - 2:15 | |
| Case Study, pt. 2 | 2:15 - 3:30 | |
| Case Study Review, pt. 2 | 3:30 - 4:00 | |
| Q&A | 4:00 - 4:15 |
Prerequisites¶
Python¶
- If you're attending this class, it's assumed you're comfortable with the material covered in the Introduction to Python for Data Science class.
- As a reminder, that course's objectives are:
- Develop comprehensive skills in the importing/exporting, wrangling, aggregating and joining of data using Python.
- Establish a mental model of the Python programming language to enable future self-learning.
- Build awareness and basic skills in the core data science area of data visualization.
Jupyter¶
- If you're attending this class, it's assumed you're comfortable with launching and using Python via Jupyter Notebooks.
- Course materials (slides, case studies, etc.) will be in Jupyter Notebooks, but you're free to use your IDE of choice when completing exercises and case studies.
Technology Setup¶
Binder¶
- This class is designed to be accessible through Binder -- a cloud-based JupyterLab hosting platform.
- As a result, no setup is technically required on your part if you would like to use Binder.
- However, Binder sessions are ephemeral and will not save your work
- You can download your notebooks if you want to keep them
- Thus, we recommend doing exercises and case studies in your own Python environment if possible.
- This way you can save your work.
Anaconda¶
- Anaconda is the easiest way to install Python 3 and Jupyter.
- If you have not yet installed Anaconda, please follow the directions in the course README.
- Be sure that all Python packages mentioned in the README are also installed:
pandas,numpy,scikit-learn, andseaborn. - This Anaconda installation will not be able to natively display the course content as slides, but we recommend it for completing exercises and the case studies.
JupyterLab¶
- JupyterLab is the application that lets us view and edit notebooks.
- JupyterLab comes with Anaconda.
Course Materials¶
- All of the material for this course can be reached from our GitHub repository.
- This repository has access to the slides, notebooks and the training source code.
- You can either access this material through Binder or by downloading the material
and opening it via Anaconda Navigator and Jupyter Lab.
Slides are Notebooks¶
- I'll be showing the material in slide format.
- These slides contain the same content as your notebooks, so you can follow along and run cells as we go.
Source Code¶
- Source code for the training can be found on GitHub.
- This repository is public so you can clone (download) and/or refer to the materials at any point in the future.
Questions¶
Are there any questions before moving on?