ML Lifecycle Management¶
"Hardest Part of ML isn’t ML, it’s Data"
![]()
Hidden Technical Debt in Machine Learning Systems (Google NIPS, 2015)
MLflow is a very comprehensive tool so we are just going to touch the surface. However, we will provide you with resources to dig deeper into MLflow.
Problem¶
The ML process can be tedious, difficult, and result in lots of technical debt.
- How do we track...
- model runs
- hyperparameter experimentations
- performance metrics
- How do we manage ML projects for...
- reproducibility
- collaboration
- How do we package ML models for downstream deployment
- How do we register models for managing...
- model lineage
- model versioning
- stage transitions (i.e. dev to stage to prod)
Intro to MLflow¶
MLflow is an open source platform designed to manage the complete Machine Learning Lifecycle.
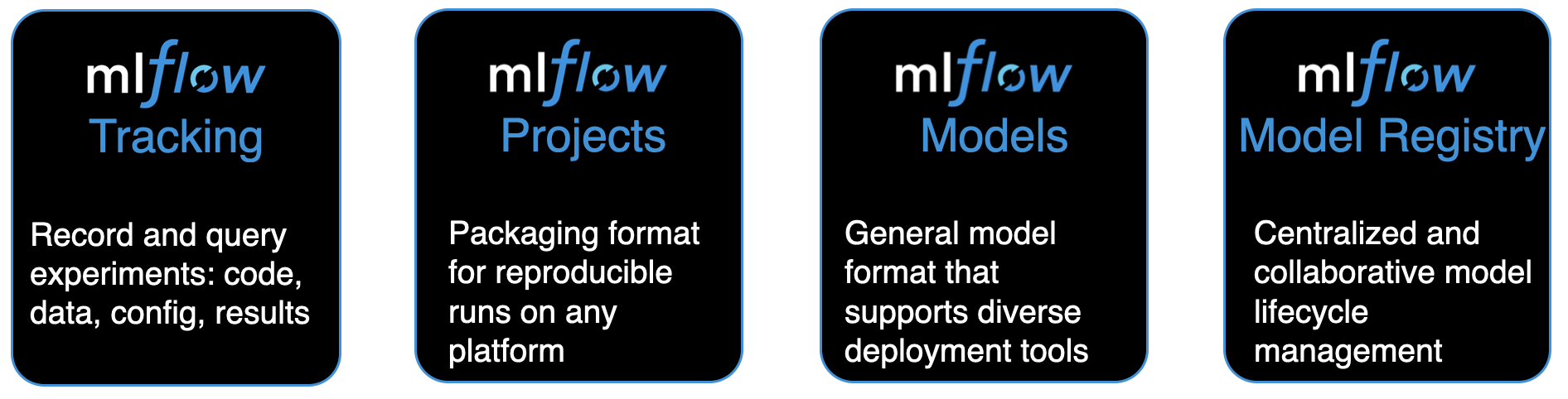
- Used heavily --> 1.7M+ monthly downloads
- Well supported --> 170+ contributors & 40 contributing organizations
- Well documented
Model Tracking¶
Key concepts in tracking:
- Date/time: Start and end time of each model run.
- Paramaters: Key-value inputs to your code.
- Metrics: Numeric values to track how your model’s loss function is converging.
- Artifacts: Output files in any format, including models.
- Source: what code ran?
There are several ways to record your modeling experiment:
- SQLAlchemy compatible database
- remotely to a tracking server
- locally
Let's create an experiment:
import mlflow
experiment = mlflow.set_experiment("Predicting income")
Tip
set_experiment will create and set an experiment if the experiment does not already exist.
Note the new local mlruns/ directory:
Before we record a model run let's import and prepare our data:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.compose import make_column_selector as selector
adult_census = pd.read_csv('../data/adult-census.csv')
# separate feature & target data
target = adult_census['class']
features = adult_census.drop(columns=['class','education-num'])
# split into train & test sets
X_train, X_test, y_train, y_test = train_test_split(
features, target, random_state=123)
# create selector object based on data type
numer_col_selector = selector(dtype_exclude=object)
cat_col_selector = selector(dtype_include=object)
# preprocessors to handle numeric and categorical features
scaler = StandardScaler()
encoder = OneHotEncoder(handle_unknown="ignore")
preprocessor = ColumnTransformer([
('one-hot-encoder', encoder, cat_col_selector(features)),
('standard_scaler', scaler, numer_col_selector(features))
])
To log a model run we use start_run() along with various other logging functions:
log_param(s): to log parameters of interestlog_metrics(s): to log model metrics of interestset_tag(s): to log decsriptive information (version number, platform ran on, etc.)log_artifact(s): allows you to log items such as data, models, files, etc.
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
mlflow.start_run(run_name='first_mlflow_run')
mlflow.log_param('max_iter', 500)
model = make_pipeline(preprocessor, LogisticRegression(max_iter=500))
_ = model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
mlflow.log_metric('accuracy', accuracy)
mlflow.end_run()
A more common approach you'll see is to use start_run() as a context manager.
with mlflow.start_run(run_name='run_as_context_mgr') as run:
mlflow.log_param('max_iter', 500)
log_reg = LogisticRegression(max_iter=500)
model = make_pipeline(preprocessor, log_reg)
_ = model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
mlflow.log_metric('accuracy', accuracy)
Question?
What other useful information could we log?
The following also logs the model type and the model itself as an artifact
with mlflow.start_run(run_name='baseline_model') as run:
mlflow.set_tag('Estimator', 'LogisticRegression')
mlflow.log_param('max_iter', 500)
log_reg = LogisticRegression(max_iter=500)
model = make_pipeline(preprocessor, log_reg)
_ = model.fit(X_train, y_train)
mlflow.sklearn.log_model(model, 'baseline_model')
accuracy = model.score(X_test, y_test)
mlflow.log_metric('accuracy', accuracy)
/opt/homebrew/anaconda3/envs/uc-python-advanced/lib/python3.11/site-packages/_distutils_hack/__init__.py:33: UserWarning: Setuptools is replacing distutils.
warnings.warn("Setuptools is replacing distutils.")
Your Turn
Log a model run using KNeighborsClassifier() as a classifier. Pick one or more parameters to log (i.e. n_neighbors. Record the ROC AUC metric using sklearn.metrics.roc_auc_score.
MLflow UI¶
We can programmatically retrieve our model run information but MLflow also provides a very nice UI that displays information.
- Remove the
#from the following line of code - Click on the local URL provided
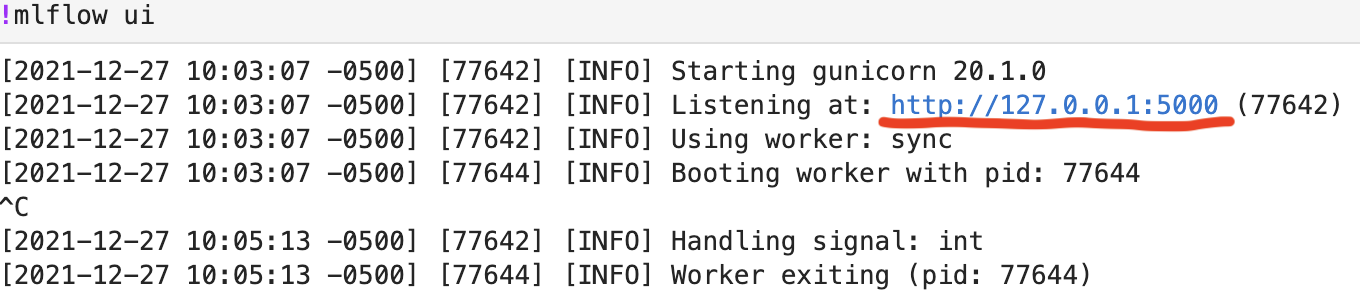
#!mlflow ui
Warning
You'll need to stop the previous code cell when you are done viewing the MLflow UI.
Auto logging¶
MLflow has built-in auto logging for many common model libraries:
- Scikit-learn
- TensorFlow & Keras
- XGBoost
- Spark ML
- Pytorch
- etc.
This can simplify our logging.
For example, the built in sklearn.autolog functionality will automatically log:
- Training score obtained by
estimator.score - Parameters obtained by
estimator.get_params - Model class name
- Fitted estimator as an artifact
# enable autologging
mlflow.sklearn.autolog()
with mlflow.start_run(run_name='autolog_run') as run:
log_reg = LogisticRegression(max_iter=500)
model = make_pipeline(preprocessor, log_reg)
_ = model.fit(X_train, y_train)
mlflow.log_metric('test_accuracy', model.score(X_test, y_test))
2024/01/07 16:09:34 WARNING mlflow.utils.autologging_utils: MLflow autologging encountered a warning: "/opt/homebrew/anaconda3/envs/uc-python-advanced/lib/python3.11/site-packages/mlflow/data/digest_utils.py:26: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead." 2024/01/07 16:09:34 WARNING mlflow.utils.autologging_utils: MLflow autologging encountered a warning: "/opt/homebrew/anaconda3/envs/uc-python-advanced/lib/python3.11/site-packages/mlflow/data/pandas_dataset.py:134: UserWarning: Hint: Inferred schema contains integer column(s). Integer columns in Python cannot represent missing values. If your input data contains missing values at inference time, it will be encoded as floats and will cause a schema enforcement error. The best way to avoid this problem is to infer the model schema based on a realistic data sample (training dataset) that includes missing values. Alternatively, you can declare integer columns as doubles (float64) whenever these columns may have missing values. See `Handling Integers With Missing Values <https://www.mlflow.org/docs/latest/models.html#handling-integers-with-missing-values>`_ for more details." 2024/01/07 16:09:36 WARNING mlflow.utils.autologging_utils: MLflow autologging encountered a warning: "/opt/homebrew/anaconda3/envs/uc-python-advanced/lib/python3.11/site-packages/mlflow/models/signature.py:212: UserWarning: Hint: Inferred schema contains integer column(s). Integer columns in Python cannot represent missing values. If your input data contains missing values at inference time, it will be encoded as floats and will cause a schema enforcement error. The best way to avoid this problem is to infer the model schema based on a realistic data sample (training dataset) that includes missing values. Alternatively, you can declare integer columns as doubles (float64) whenever these columns may have missing values. See `Handling Integers With Missing Values <https://www.mlflow.org/docs/latest/models.html#handling-integers-with-missing-values>`_ for more details."
Let's check out this auto-logged run in the UI. You'll notice some additional information logged.
#!mlflow ui
Your Turn
Re-run the KNeighborsClassifier() classifier model from the previous your turn; however, use mlflow.sklearn.autolog for autologging.
Hyperparameter tuning¶
So far, we've just been logging individual runs.
However, MLflow makes it easy to track hyperparameter search experiments:
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
# basic model object
knn = KNeighborsClassifier()
# Create grid of hyperparameter values
hyper_grid = {'knn__n_neighbors': [5, 10, 15, 20]}
# create preprocessor & modeling pipeline
pipeline = Pipeline([('preprocessor', preprocessor), ('knn', knn)])
# enable autologging before tuning the KNN model
mlflow.sklearn.autolog()
with mlflow.start_run(run_name='knn_grid_search') as run:
results = GridSearchCV(
pipeline, hyper_grid, cv=5, scoring='roc_auc', n_jobs=-1
).fit(X_train, y_train)
2024/01/07 16:09:37 WARNING mlflow.utils.autologging_utils: MLflow autologging encountered a warning: "/opt/homebrew/anaconda3/envs/uc-python-advanced/lib/python3.11/site-packages/mlflow/data/digest_utils.py:26: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead." 2024/01/07 16:09:37 WARNING mlflow.utils.autologging_utils: MLflow autologging encountered a warning: "/opt/homebrew/anaconda3/envs/uc-python-advanced/lib/python3.11/site-packages/mlflow/data/pandas_dataset.py:134: UserWarning: Hint: Inferred schema contains integer column(s). Integer columns in Python cannot represent missing values. If your input data contains missing values at inference time, it will be encoded as floats and will cause a schema enforcement error. The best way to avoid this problem is to infer the model schema based on a realistic data sample (training dataset) that includes missing values. Alternatively, you can declare integer columns as doubles (float64) whenever these columns may have missing values. See `Handling Integers With Missing Values <https://www.mlflow.org/docs/latest/models.html#handling-integers-with-missing-values>`_ for more details." 2024/01/07 16:11:58 WARNING mlflow.utils.autologging_utils: MLflow autologging encountered a warning: "/opt/homebrew/anaconda3/envs/uc-python-advanced/lib/python3.11/site-packages/mlflow/models/signature.py:212: UserWarning: Hint: Inferred schema contains integer column(s). Integer columns in Python cannot represent missing values. If your input data contains missing values at inference time, it will be encoded as floats and will cause a schema enforcement error. The best way to avoid this problem is to infer the model schema based on a realistic data sample (training dataset) that includes missing values. Alternatively, you can declare integer columns as doubles (float64) whenever these columns may have missing values. See `Handling Integers With Missing Values <https://www.mlflow.org/docs/latest/models.html#handling-integers-with-missing-values>`_ for more details." 2024/01/07 16:12:00 INFO mlflow.sklearn.utils: Logging the 5 best runs, no runs will be omitted.
If we look at the MLflow UI we'll notice that autologging a parameter search results in a single parent run and nested child runs, which contains:
- Parent
- Training score
- Best parameter combination
- Fitted best estimator
- and more
- Child
- CV test score for each parameter combination
#!mlflow ui
Your Turn
Based on the results we found, run another grid search with adjusted n_neighbors and see if the results improve.
Accessing run information¶
We can programmatically access our mlflow run information:
df = mlflow.search_runs(experiment_ids=experiment.experiment_id)
df.head(3)
| run_id | experiment_id | status | artifact_uri | start_time | end_time | metrics.std_score_time | metrics.std_test_score | metrics.std_fit_time | metrics.rank_test_score | ... | tags.mlflow.runName | tags.estimator_name | tags.mlflow.source.type | tags.estimator_class | tags.mlflow.autologging | tags.mlflow.source.name | tags.mlflow.user | tags.mlflow.parentRunId | tags.mlflow.log-model.history | tags.Estimator | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 02fc5f7cf19d433ab194e17c9796d984 | 756538018307011023 | FINISHED | file:///Users/jamescunningham/Projects/advance... | 2024-01-07 21:09:37.743000+00:00 | 2024-01-07 21:12:00.166000+00:00 | 0.033195 | 0.004886 | 0.007759 | 4.0 | ... | resilient-bird-785 | Pipeline | LOCAL | sklearn.pipeline.Pipeline | sklearn | /opt/homebrew/anaconda3/envs/uc-python-advance... | jamescunningham | d9324a90f4ab4762b69110d473fd3aa1 | None | None |
| 1 | 432ab39a489b48e28c9fbd7262e11799 | 756538018307011023 | FINISHED | file:///Users/jamescunningham/Projects/advance... | 2024-01-07 21:09:37.743000+00:00 | 2024-01-07 21:12:00.166000+00:00 | 0.041490 | 0.002964 | 0.002496 | 1.0 | ... | skittish-cod-799 | Pipeline | LOCAL | sklearn.pipeline.Pipeline | sklearn | /opt/homebrew/anaconda3/envs/uc-python-advance... | jamescunningham | d9324a90f4ab4762b69110d473fd3aa1 | None | None |
| 2 | 43ec7480d8114fc1b2f998f4a69d008d | 756538018307011023 | FINISHED | file:///Users/jamescunningham/Projects/advance... | 2024-01-07 21:09:37.743000+00:00 | 2024-01-07 21:12:00.166000+00:00 | 0.101619 | 0.003366 | 0.001141 | 2.0 | ... | valuable-koi-692 | Pipeline | LOCAL | sklearn.pipeline.Pipeline | sklearn | /opt/homebrew/anaconda3/envs/uc-python-advance... | jamescunningham | d9324a90f4ab4762b69110d473fd3aa1 | None | None |
3 rows × 117 columns
This allows us to query for the KNN grid search run and access the run ID:
model_filter = df['tags.mlflow.runName'] == 'knn_grid_search'
run_id = df.loc[model_filter, 'run_id'].iloc[-1]
Which we can use to load the the model:
model_path = (
f'mlruns/{experiment.experiment_id}/{run_id}'
'/artifacts/best_estimator'
)
model = mlflow.sklearn.load_model(model_path)
model
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('one-hot-encoder',
OneHotEncoder(handle_unknown='ignore'),
['workclass', 'education',
'marital-status',
'occupation', 'relationship',
'race', 'sex',
'native-country']),
('standard_scaler',
StandardScaler(),
['age', 'capital-gain',
'capital-loss',
'hours-per-week'])])),
('knn', KNeighborsClassifier(n_neighbors=20))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('one-hot-encoder',
OneHotEncoder(handle_unknown='ignore'),
['workclass', 'education',
'marital-status',
'occupation', 'relationship',
'race', 'sex',
'native-country']),
('standard_scaler',
StandardScaler(),
['age', 'capital-gain',
'capital-loss',
'hours-per-week'])])),
('knn', KNeighborsClassifier(n_neighbors=20))])ColumnTransformer(transformers=[('one-hot-encoder',
OneHotEncoder(handle_unknown='ignore'),
['workclass', 'education', 'marital-status',
'occupation', 'relationship', 'race', 'sex',
'native-country']),
('standard_scaler', StandardScaler(),
['age', 'capital-gain', 'capital-loss',
'hours-per-week'])])['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'native-country']
OneHotEncoder(handle_unknown='ignore')
['age', 'capital-gain', 'capital-loss', 'hours-per-week']
StandardScaler()
KNeighborsClassifier(n_neighbors=20)
However, using the Model Registry is a more sophisticated approach for saving and accessing models.
Registering models¶
MLflow provides a Model Registry that provides a centralized and collaborative approach to model lifecycle management.
Note
You can register models programmatically or via the MLflow UI. However, to do so locally requires additional setup that we don't have time for. If using one of the main cloud providers (i.e. Databricks on AWS, Azure, or GCP) the setup is already done and model registration is very straightforward.
One Collaborative Hub: The Model Registry provides a central hub for making models discoverable, improving collaboration and knowledge sharing across the organization.
Manage the entire Model Lifecycle (MLOps): The Model Registry provides lifecycle management for models from experimentation to deployment, improving reliability and robustness of the model deployment process.
- Overview of active model versions and their deployment stage
- Request/Approval workflow for transitioning deployment stages
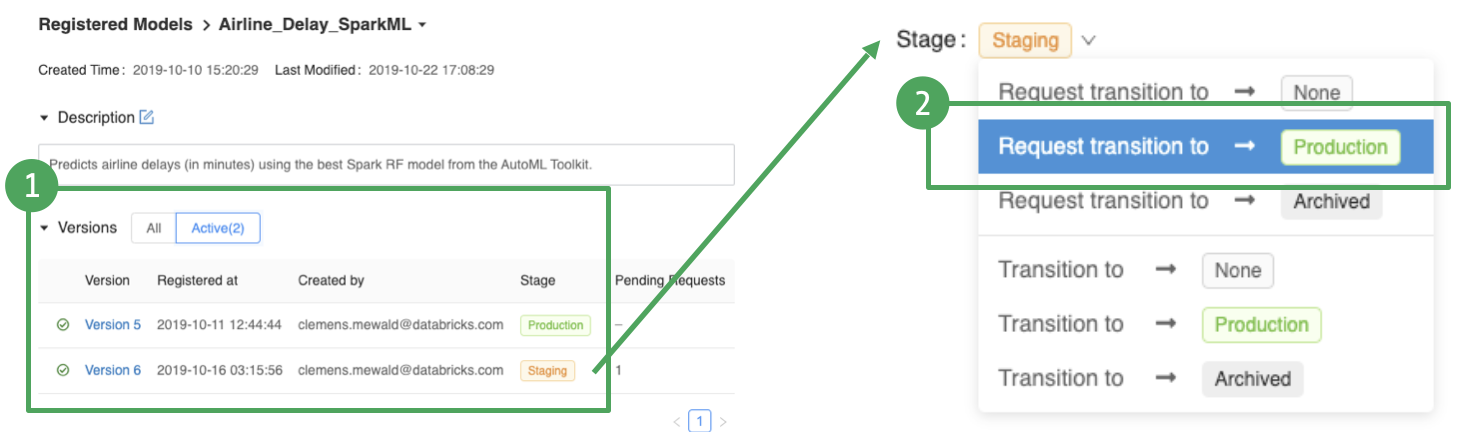
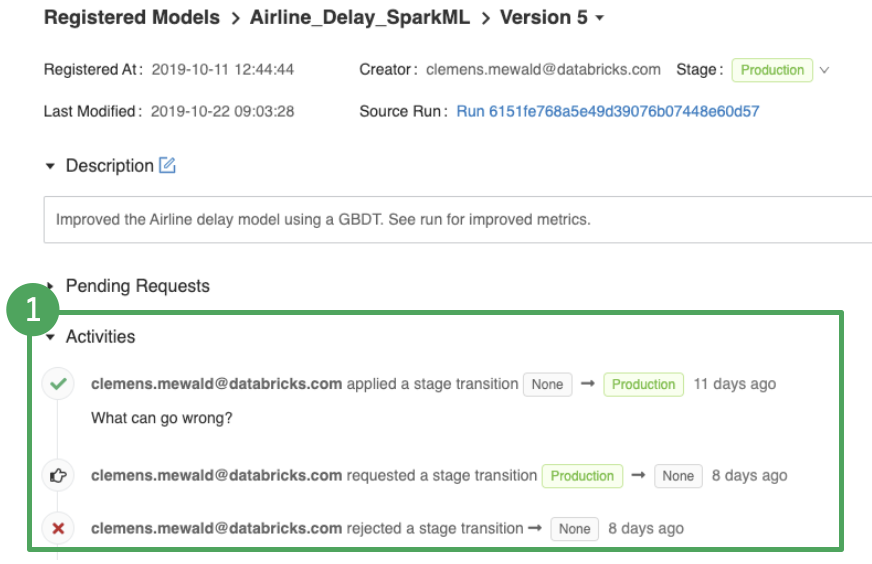
Visibility and Governance: The Model Registry provides full visibility into the deployment stage of all models, who requested and approved changes, allowing for full governance and auditability.
- Full activity log of stage transition requests, approvals, etc.
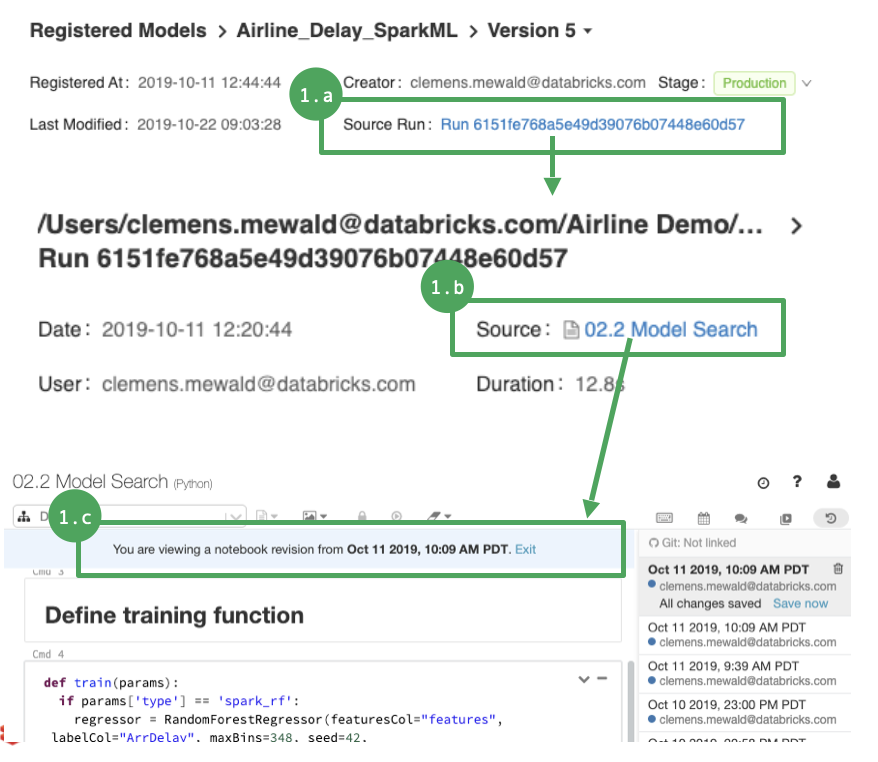
Full provenance from Model marked production in the Registry to ...
- Run that produced the model
- Notebook that produced the run
- Exact revision history of the notebook that produced the run
Wrapping up¶
This module introduced you to MLflow for machine learning lifecycle management. We provided a very brief introduction to MLflow for...
- managing model experiments,
- tracking hyperparameter tuning,
- registering and serving models.
MLflow provides so much more than we have time to cover; however, this should give you a decent foundation to build upon.
We recommend the following resources to learn more: